Unicode wants to save scripts by standardizing them
Bizarre as well as strange, the Unicode language aims at gathering and preserving writings… by unifying them with a code system. If the idea is far-fetched, it is nevertheless beautiful and useful. On closer inspection, the method is not so standardized; it couldn’t be done without the hand of man, and meets cultures’ resistance.
Numbers and letters
In the wonderful world of computers, signs and characters are represented with 0 and 1. These binary-coded numbers formalize writings in the memory of the device to transcribe them on the screen.
The great revolution of the numeric keyboard, unlike its ancestor the typewriter, is that it is not limited to the characters written on the keys. On a computer, it is possible to switch the keyboard from AZERTY to QWERTY by clicking on a button, or to create new characters using several keys, such as “•” with alt + @ or “œ” with alt + o for example. The numeric character is therefore not limited to a single key. The numeric coded language thus offers unlimited possibilities.
Houston, we’ve got a problem
Since the 1960s, the ASCII code, American Standard Code for Information Interchange, has been used in most cases. Invented by our American friends, it is based – logically – on their alphabet. ASCII offers 95 printable characters, numbers from 0 to 9, and mathematical and punctuation symbols. Check it out :

Minor problem: this system is only suitable for English speakers because it is not adapted to other special characters in other languages such as œ or ç in French or ä, ü, ß in German. It neglects non-alphabetic scripts such as Chinese, Hindi or Osmanya to name only 3. It is then difficult to write beautiful sentences such as: à Noël où un zéphyr haï me vêt de glaçons würmiens, je dîne d’exquis rôtis de bœuf à l’aÿ d’âge mûr, & cætera. Oh dear, what a pity.
Another limitation, but not the least, is that ASCII character encoding is unfortunately limited in its use since several characters can have the same code. Depending on the messaging systems or websites used, completely different characters or hollowed-out rectangles may appear (they are called “tofu” because of their resemblance with… tofu). This still happens today, even though Unicode has been around for 30 years.
One can imagine that there must have been some small problems when an electronic notes indicated a “monetary sign” and that it varied from country to country instead of remaining faithful to the original value. A reader in the United States would then read an amount in $ and his British counterpart would see it in £. Ha, the limits of globalization…
Standardizing scripts with Unicode?
To make it simple and not too geeky, Unicode was invented to overcome these problems. Created in 1991, this computer standard brought together the most notable private and public partners in the field of information technology. Its aim is to code, represent and process any glyph in any language and on any medium or software. And thus to use easily any type of writing on a digital support, such as ⵉ ढ़ ڞ ぽ ༇ ꠚ 🌴 𑀙 𒋞 ꐀ which you can find on unicodepedia.
Unicode aims to harmonize writings using codes, in a square format. Today there are around 150 000 signs (143,859 to be exact) from 154 writings, and 3304 emoticons, visible on decodeunicode or the official Unicode site (which is more technical and less visual) or on unicode-table, which classifies alphabets or emojis. Since the boom of smartphones, in 2014, Unicode is updated every year with new characters, mainly emoticons.
Creating an emoji
If you feel like it, you can easily create and submit an emoji (a Breton flag for example would be very useful #emojiBZH). What, here’s a fondue emoji since 2020! We found the example of the emoji lama creation folder proposed in 2017 in which it says that the emoticon would be very useful to make puns in Spanish (what’s your name is written como te llamas, and llamas also means lama). A Twitter user wrote in 2015 that he “hated the world for not having an emoji lama”, provoking 5,800 likes and 2,700 shares. The emoji was added in 2018 under the code U+1F999. Phew.
We still can’t find a penis emoji (which is a symbol often used in the world) so; oblivion or censorship? We have got our little idea.

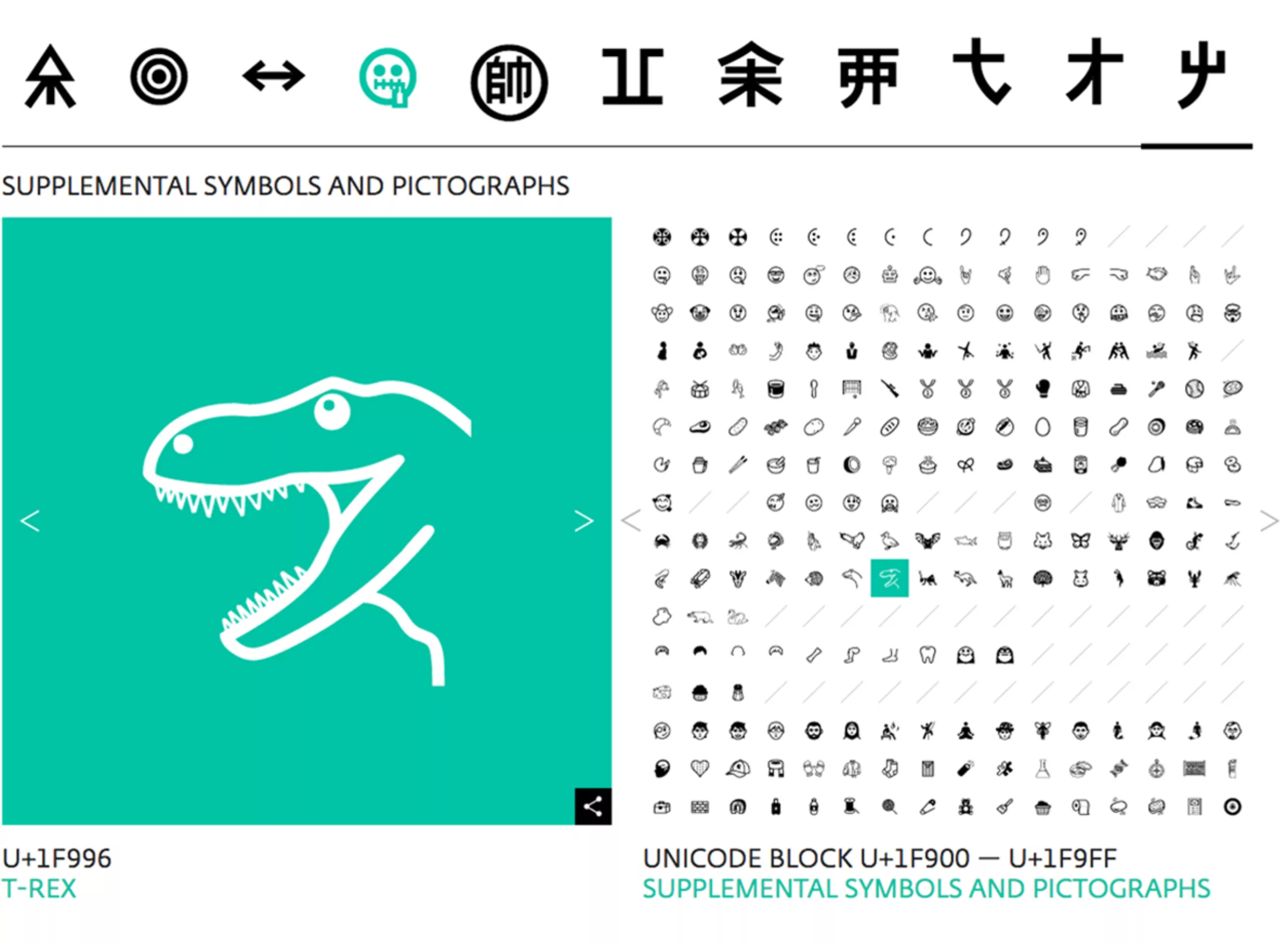
The role of Unicode is not only to standardize writing and make it readable everywhere, but also to digitize characters from dead or little spoken languages to preserve them. It’ s a bit like a huge library of the world’s linguistic heritage. It took no less than 27 years to fully create the 146 existing scripts! This represents a colossal amount of research and creation work.
From cultural design to standardized design
In a publication by developers working on Unicode in Stanford in 1993, it reads that the original idea was to develop a harmonization of typographic rendering, to avoid text distortions or surprises (such as tofu) in multilingual documents, or to have mathematical signs and letters of different weights in the text. In reality, this is much more complicated than you might think. The epic thing about this Unicode writing system – which is meant to be standardized – is that the typographic work to create the glyphs is actually done by hand (digitally). The writing is not yet automated! On the other hand, it must comply with precise specifications to frame this creation.
Lucida Sans for Latin languages
Unicode meets standards and rules in its realization, validated by a technical committee. When Unicode was created in 91, the Lucida Sans typography was chosen as a basis to develop the characters. It is a modern typography but easily resonates with the handwritten style. The choice was made to use a sans serif, with a neutral style, which is simpler and purer than a serif.
Sans serif typefaces reach the essence of the typeface and make it possible to better distinguish the glyphs from each other, without parasitic embellishments. They also have less cultural-historical background. This is where we see the full scope of such research work and the questions raised by such a design project.
The Lucida Sans Console was created in response to the problems associated with digital word processing, including the risk of overlapping capital accents on top lines of text, or poor character reading. The Console is thus a monospace (it has the same spacing in the width for each letter), with a noticeable difference between the heights of upper and lower case letters, or finer accents on upper case letters. For the typographers who read us, it is based on Lucida Sans Unicode and Lucida Sans Typewriter.
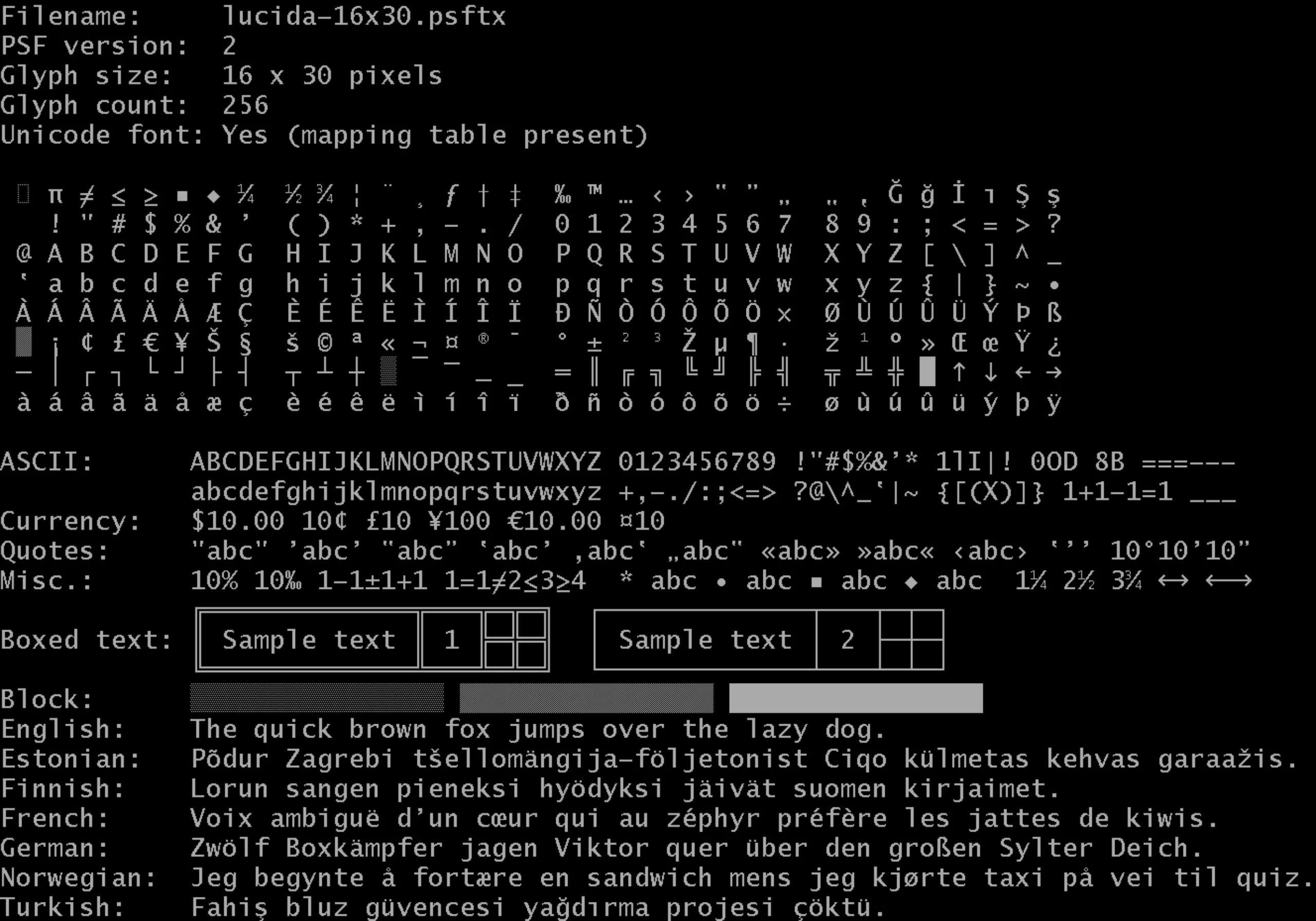
But if it is almost easy to decline Latin languages thanks to a basic typography, it is much more complicated to tackle other characters (oriental for example) or ideograms (of Asian languages for example).
Ethnological and linguistic work for non-Latin languages
In non-Latin languages, a character (letter defined by a code) does not give only one glyph (sign, representative drawing). That is to say that one letter can correspond to several glyphs variations. For example, for the Arabic alphabet, most letters have 4 glyphs depending on whether it is written at the beginning, in the middle, used alone or at the end of a word.
In Latin language, in Unicode, the letter has a different code depending on whether it is upper-case -A- or lower-case -a-, because it is visually different, such as -c- or -ç- for example. On the other hand, an italic a or a bold a will have the same code: Unicode considers the shape, not the allographs (variants of the same glyph). It is therefore sometimes necessary to design several glyphs for non-latin characters. We show below an example with the letter “veh” ( ۋ in Arabic), declined according to its 4 forms.

Moreover, if we continue on the logic of standardized characters, then the Chinese, Korean and Japanese ideograms -which are initially the same- should be able to correspond to these 3 languages. A bit like the Latin alphabet which is suitable for writing Spanish, French or English (except for a few signs or accents). But the culture cannot be standardized so easily. The cultural variations of each country are such that ideograms actually give different scripts in China, Korea and Japan depending on whether one writes with hanzi, hanji or kanji characters. To design such signs, called CJK in Unicode, for Chinese, Japanese, Korean, it is therefore imperative to collaborate with local designers and merge them with existing local typographies.

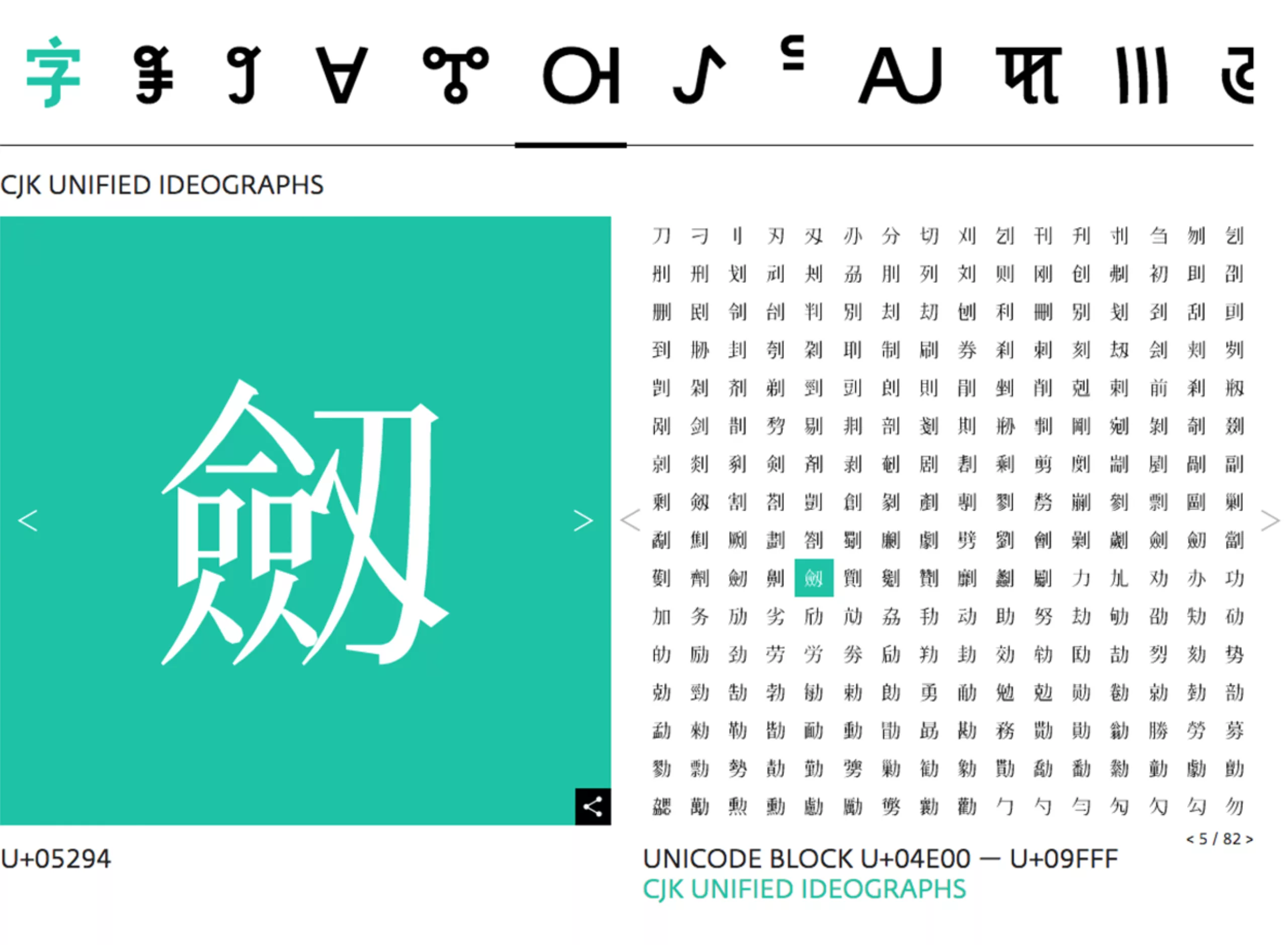
In addition, rare or extinct languages require an enormous amount of research work. Concrete examples will be given in the next section below. Designers working on glyphs, most of which are manuscripts, do a real job as linguists and ethnologists. It is necessary to look into the creation of new design rules, to understand character tracings, to take into account legibility, variable initial forms. For the typographer, it is a question of understanding the hand, the eye and the brain of his predecessors. The shape of the letter is a living idea to be transcribed, very difficult to standardize.
And where humans shine with their creative genius, unlike the machine, and where we thought we had standardized everything, we are constantly discovering writings that are exceptions to the rule and are still very confusing to code. Moreover, man even continues to invent new writings (in Kenya for example, the Luo was created in 2009)!
Un Unicode pour les rassembler tous
The Script Encoding Initiative (SEI) is a research project aimed at coding letters from ethnic minorities or dead languages in order to bring them into the digital age. This promotes education in these native languages and breaks down computer barriers. For dead languages, it facilitates online research and education.
Based on this research, the Missing Script Project (MSP) proposed a Unicode glyph for each of the missing alphabets, mostly the character A. The MSP site, the World Writing Systems, strives to gather all the writings and digital systems of the world, extinct or still spoken today. There are a total of 292 human writing systems, half of which are not yet listed in Unicode. Below, vai, latin, cuneiform, lisu, ancient persian, ol chiki, bamum, and ideograms from languages from the 4 corners of the globe.

This research and typographic work was conducted jointly by the Atelier National de Recherche Typographique de Nancy, the Institut Designlabor Gutenberg in Germany, and the Script Encoding Initiative at UC Berkley in the United States.
It took 18 months to propose 146 main glyphs for these 146 missing alphabets, and the creation of 66 different typographies. Here are a few of them:

Johannes Bergerhausen and Morgane Pierson, who worked on the missing scripts project, say that this work of harmonizing the scripts is far from simple. First of all, they analyzed and cross-referenced different sources to identify the letters, and had them validated by writing specialists. Then, the signs often vary according to dialects, regions or simply the handwriting of the person who wrote them. Since Unicode is standardized in its rendering, it is sometimes necessary to modify the appearance or proportions of the signs to fit into the imaginary square that serves as a standard. An elongated sign must thus be shortened, to “not poke out”.
This is what the researchers explain in a conference about the missing scripts project on YouTube, a capture of which is shown below. On the left, the patterns from the engravings, on the right the unicode symbol proposals.


We understand here the work of harmonization of the sign based on the different existing scripts.
This board shows the feedback from writing specialists, who help researchers defining the right Unicode glyph.

And to end on a high note, here is a graphic overview of all the languages of the world, living and dead. This silk-screen printed poster is available for sale on the world writing system.

To go further on this momentum of cultural but standardized typographies, we also talked about Google’s Noto (no tofu) typeface in our article about the typeface of the future. The latter is a typographic project that consists in digitally designing in Unicode little spoken or even dead languages, and making them alive not only on stones but on screens. Less complete than the MSP, it converges towards the same desire to preserve the world’s writings system.
On the subject
-
Hobo signs, the secret language of America’s wanderers
Resourceful and itinerant, the hobos developed a secret language system, doomed to disappear, to leave clues for their fellow hobos.
-

Writing with images: from pictographic scripts to emojis
The first writings were drawings, and universal languages have always used images to communicate.
-

Creating a universal language
In their search for a universal language, Leibniz and his disciples may have attempted to create the impossible. And yet…