L’Unicode veut sauver les écritures en les standardisant
Bizarre autant qu’étrange, le langage Unicode vise à rassembler et préserver les écritures… en les unifiant par un système de code. Si l’idée est farfelue, elle est néanmoins belle et utile. Et à bien y regarder, la méthode n’est pas si standardisée ; elle ne pourrait se faire sans la main humaine, et elle se heurte à la résistance des cultures.
Des chiffres et des lettres
Dans le monde merveilleux des ordinateurs, on représente les signes et caractères à l’aide de 0 et de 1. Ces chiffres codés en binaire formalisent des écritures dans la mémoire de l’appareil pour les retranscrire sur l’écran.
La grande révolution du clavier numérique, contrairement à son ancêtre le clavier de machine à écrire, est de ne pas se limiter aux caractères inscrits sur les touches. Sur un ordinateur, il est possible de changer de clavier et de passer de l’AZERTY au QWERTY en cliquant sur un bouton, ou de créer de nouveaux caractères à l’aide de plusieurs touches, comme “•” avec alt + @ ou “œ” avec alt + o par exemple. Le caractère numérique n’est donc pas limité à une seule touche. Le langage codé numérique offre ainsi des possibilités illimitées.
Houston, we’ve got a problem
Depuis les années 60 on a utilisé en majorité le code ASCII, American Standard Code for Information Interchange (Code américain normalisé pour l’échange d’information). Inventé par nos amis les américains, il se base -en toute logique- sur leur alphabet. ASCII propose 95 caractères imprimables, les chiffres de 0 à 9, et des symboles mathématiques et de ponctuation. Voyez plutôt :

Petit problème : ce système ne convient qu’aux anglophones car il n’est pas adapté aux autres caractères spéciaux en d’autres langues comme les œ ou ç en français ou ä, ü, ß en allemand. Il délaisse carrément les écritures non alphabétiques comme les caractères Chinois, Hindî ou Osmanya pour n’en citer que 3. Difficile alors d’écrire de belles phrases comme : à Noël où un zéphyr haï me vêt de glaçons würmiens, je dîne d’exquis rôtis de bœuf à l’aÿ d’âge mûr, & cætera. Dommage.
Autre limite mais pas des moindres, le codage de caractère ASCII est malheureusement limité dans son utilisation puisque plusieurs caractères peuvent avoir le même code. Suivant les messageries ou les sites Internet utilisés, des caractères complètement différents ou des rectangles évidés peuvent surgir (on les appelle “tofu” à cause de leur ressemblance avec… le tofu). C’est encore le cas aujourd’hui, même si l’Unicode existe depuis 30 ans.
On imagine qu’il est sûrement arrivé quelques petits problèmes lorsqu’une note électronique indiquait un “signe monétaire” et que celui-ci variait suivant les pays au lieu de rester fidèle au montant d’origine. Un lecteur aux États-Unis lisait alors un montant en $ et son acolyte Britannique le voyait en £. Ha, les limites de la mondialisation…
Standardiser les écritures avec l’Unicode ?
Pour faire simple et pas trop geek, l’Unicode a donc été inventé pour pallier à ces problèmes. Créé en 1991, ce standard informatique regroupant les partenaires privés et publiques les plus notables de l’informatique, permet de coder, représenter et traiter n’importe quel signe dans n’importe quelle langue et sur n’importe quel support ou logiciel. Et donc d’utiliser facilement n’importe quel type d’écriture sur un support numérique, comme les glyphes ⵉ ढ़ ڞ ぽ ༇ 🜦 ꠚ 🌴 ⻨ 𑀙 𒋞 ꐀ que vous trouverez sur le site unicodepedia.
L’Unicode vise l’harmonisation des écritures à l’aide de blocs de codes dans un format carré. Il existe à ce jour autour de 150 000 signes (143,859 pour être exacte) issus de 154 écritures, et 3304 émoticônes, visibles sur decodeunicode ou le site officiel de l’Unicode (qui est plus technique et moins visuel) ou encore sur unicode-table, qui classifie les alphabets ou les émojis. Depuis le boom des smartphones, dès 2014, l’Unicode est mis à jour chaque année avec de nouveaux caractères, principalement des émoticônes.
Créer une émoticône
Si le cœur vous en dit, vous pouvez parfaitement créer et soumettre bénévolement un émoji (un drapeau breton par exemple serait bien utile #emojiBZH). Il y a bien un émoji fondue depuis 2020 ! Nous avons trouvé un exemple du dossier de création de l’emoji lama proposé en 2017 dans lequel on lit que l’émoticône serait bien utile pour faire des jeux de mots en espagnol (comment tu t’appelles s’écrit como te llamas, et llamas veut aussi dire lama). Un usager twitter écrivait en 2015 qu’il “haïssait tout le monde pour l’absence d’émoji lama”, provoquant 5 800 likes et 2 700 partages. L’émoji a été rajouté en 2018 sous le code U+1F999. Ouf.
On ne trouve en revanche toujours pas d’émoji pénis (qui est pourtant un symbole bien souvent utilisé dans le monde) alors ; oubli ou censure ? On a notre petite idée.

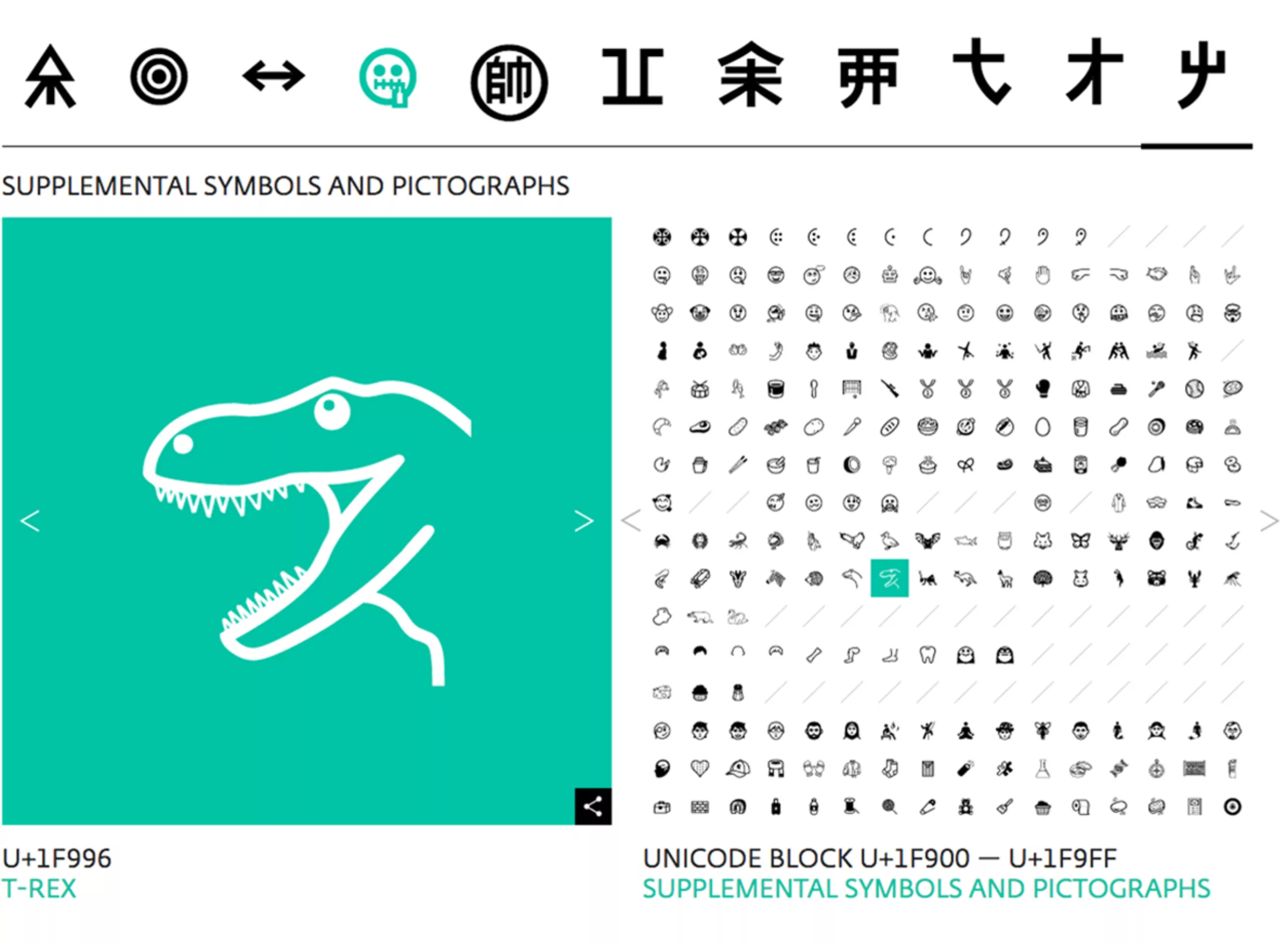
Le rôle de l’Unicode n’est pas seulement de standardiser l’écriture et de la rendre lisible de partout, mais c’est aussi de digitaliser des caractères de langues mortes ou peu parlées pour les conserver. Un peu comme une immense bibliothèque du patrimoine linguistique mondial. Il a fallu pas moins de 27 ans pour créer intégralement les 146 écritures existantes ! Cela représente un travail de recherche et de création colossal.
Du design culturel au design standardisé
Dans une publication de développeurs travaillant sur l’Unicode à Standford en 1993, on lit que l’idée originelle était de développer une harmonisation du rendu typographique, pour éviter les distorsions de texte ou les surprises (de type tofu) dans les documents multilingues, ou encore d’avoir des signes mathématiques et des lettres de graisses différentes dans le texte. Dans les faits, cela est bien plus compliqué qu’on ne le pense. Le comble de ce système d’écriture Unicode -qui se veut standardisé- est que le travail typographique pour créer les glyphes est bel et bien fait à la main (digitalement). L’écriture n’est donc pas encore automatisée ! En revanche, elle s’inscrit dans un cahier des charges précis pour encadrer cette création.
La Lucida Sans pour les langues latines
L’Unicode répond à des standards et des règles dans sa réalisation, validés par un commité technique. Lors de la création de l’Unicode en 91, la typographie Lucida Sans a été choisie comme base pour développer les caractères. C’est une typographie moderne mais qui résonne facilement avec le style manuscrit. Le choix a été porté sur une sans sérif, au style neutre, plus simple et plus pur qu’une sérif.
Les typographies sans serif vont à l’essence du caractère et permettent de mieux distinguer les glyphes entre eux, sans fioritures parasites. Elles ont également moins de bagage historico-culturel. C’est là que l’on voit toute l’étendue du travail de recherche et des questions que soulèvent un tel projet de design.
La Lucida Sans Console a été créée en réponse aux problèmes liés au traitement de texte digital, avec notamment le risque de superposition d’accents de majuscules sur les lignes de texte supérieures, ou la mauvaise lecture de caractères. La Console est ainsi une monospace (elle comporte le même espacement dans la largeur pour chaque lettre), avec une différence notable entre les hauteurs de majuscules et minuscules, ou des accents plus fins sur les majuscules. Pour les typographes qui nous lisent, elle est créée à partir de la Lucida Sans Unicode et de la Lucida Sans Typewriter.
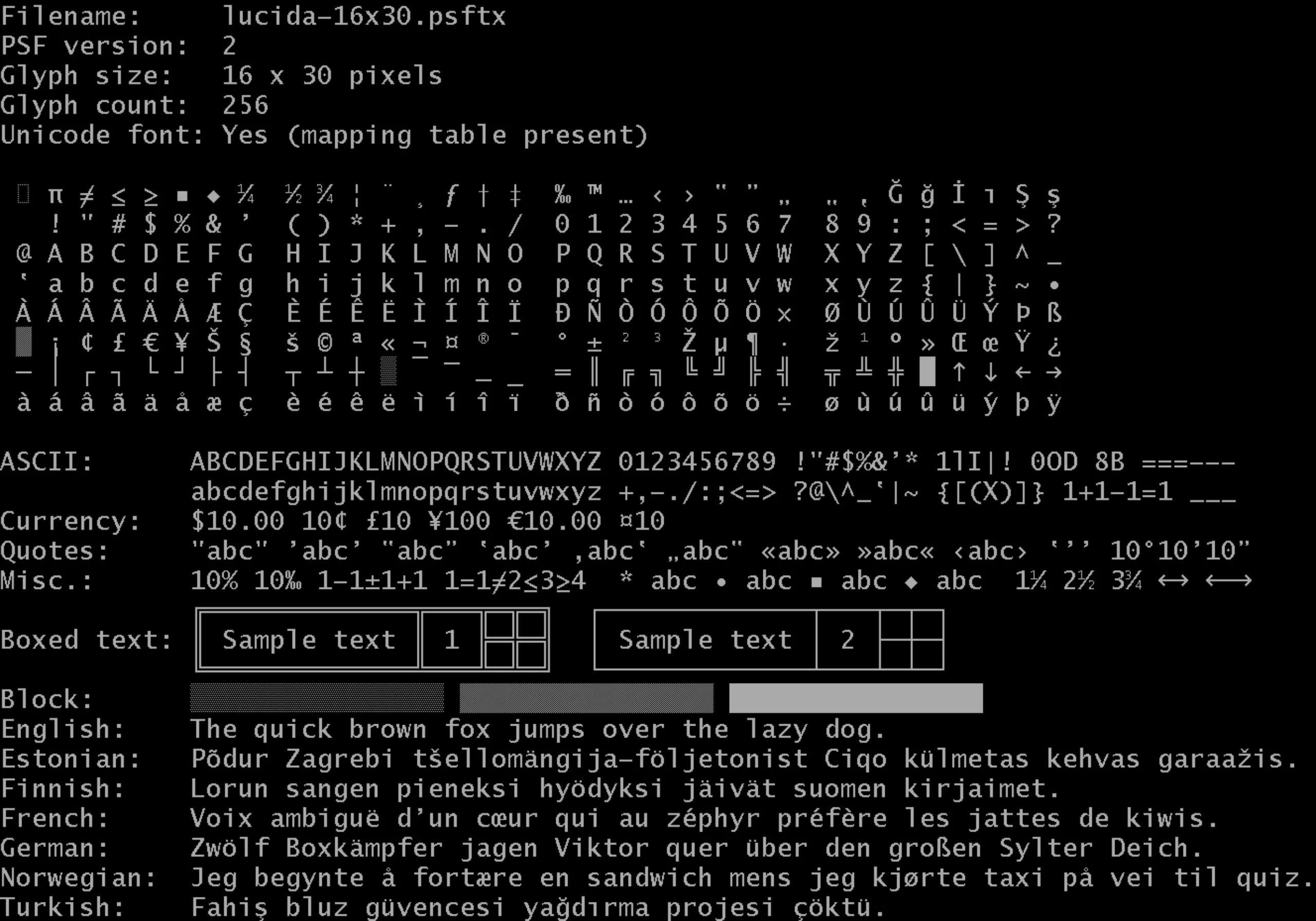
Mais s’il est à peu près facile de décliner les langues latines grâce à une typographie de base, il est bien plus compliqué de s’attaquer aux autres caractères (comme les orientaux) ou aux idéogrammes (de langues asiatiques par exemple).
Un travail ethnologique et linguistique pour les non-latines
Dans les langues non-latines, un caractère (lettre définie par un code) ne donne pas qu’un seul glyphe (signe, dessin représentatif). C’est à dire qu’une lettre peut correspondre à plusieurs déclinaisons ou variations de glyphes. Par exemple, pour l’alphabet arabe, la lettre alif (a) possède 4 glyphes selon qu’elle s’écrit au début, au milieu, seule ou en fin de mot.
En langue latine, dans l’Unicode, la lettre possède un code différent selon qu’elle est majuscule -A- ou minuscule -a-, car elle est visuellement différente, comme le -c- ou le -ç- par exemple. En revanche, un a italique ou un a en gras aura le même code : l’Unicode prend en compte la forme, pas les allographes (variantes d’un même glyphe). Il faut donc parfois concevoir plusieurs glyphes pour les langues non-latines. On voit ici un exemple avec la lettre “veh” ( ۋ en arabe), déclinée suivant ses 4 formes.

De plus, si l’on continue sur la logique de caractères standardisés, alors les idéogrammes Chinois, Coréens et Japonais -qui sont initialement les mêmes- devraient pouvoir correspondre à ces 3 langues. Un peu comme l’alphabet latin qui convient pour l’écriture de l’espagnol, du français ou de l’anglais (à quelques signes ou accents près). Mais la culture ne se laisse pas standardiser si facilement. Les variations culturelles de chaque pays sont telles que les idéogrammes donnent en réalité des écritures différentes en Chine, Corée et Japon suivant que l’on écrit avec des caractères hanzi, hanji ou kanji. Pour concevoir ce genre de signes, appelés CJK en Unicode, pour Chinese, Japanese, Korean, il faut donc impérativement collaborer avec des designers locaux et les fusionner avec des typographies locales existantes.

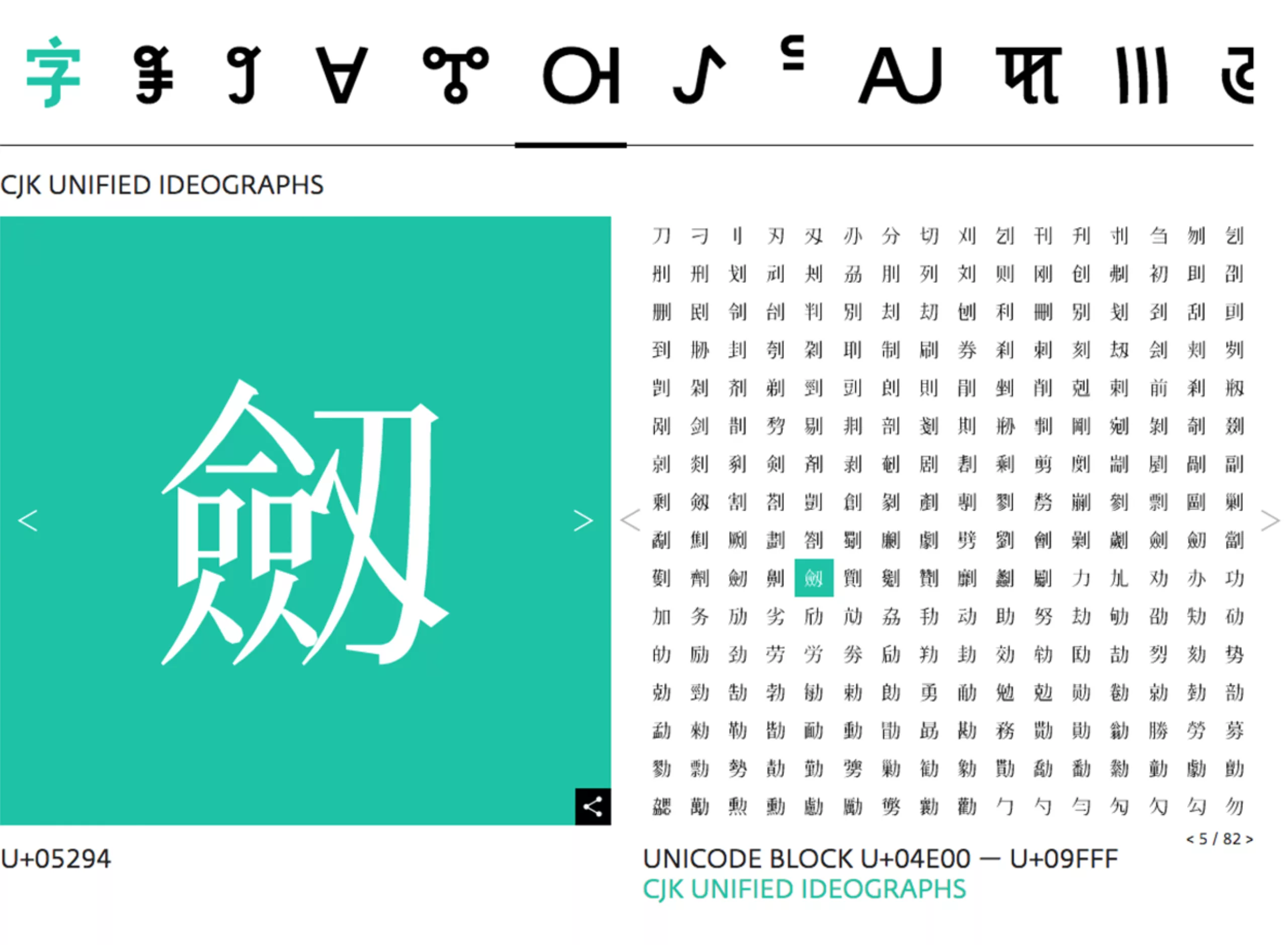
En outre, les langues rares ou éteintes demandent un travail de recherche énorme. On donnera des exemples concrets dans la section suivante, un peu plus bas. Les designers qui se penchent sur des glyphes pour la plupart manuscrits font un réel travail de linguiste et d’ethnologue. Il faut se pencher sur la création de nouvelles règles de design, comprendre des tracés de caractères, prendre en compte la lisibilité, les formes initiales variables. Pour le typographe, il s’agit de comprendre la main, l’œil et le cerveau de ses prédécesseurs. La forme de la lettre est une idée vivante à retranscrire, bien difficilement standardisable.
Et là où l’humain brille par son génie créatif contrairement à la machine, et lors que l’on croyait avoir tout normalisé, on découvre sans cesse des écritures qui comportent des exceptions à la règle et qui sont encore très déroutantes à coder. D’ailleurs, les humains continuent même à inventer de nouvelles écritures (au Kenya par exemple, le Luo a été créé en 2009) !
Un Unicode pour les rassembler tous
Le Script Encoding Initiative (SEI) est un projet de recherche visant à coder les lettres issues de minorités ethniques ou de langues mortes afin de les faire accéder à l’ère numérique. Cela permet ainsi de promouvoir une éducation dans lesdites langues natives, et de faire tomber les barrières informatiques. Pour les langues mortes, cela facilite les travaux de recherche et d’éducation en ligne.
En se basant sur ces recherches, le Missing Script Project (MSP, le projet des alphabets manquants) a proposé un glyphe en Unicode pour chacun des alphabets manquants, majoritairement le caractère A. Le site du MSP, le World Writing Systems, s’évertue à rassembler toutes les écritures et systèmes numériques du monde, éteints ou encore parlés aujourd’hui. On compte 292 systèmes d’écritures humaines au total, dont la moitié ne sont pas encore répertoriées en Unicode. Ci-dessous, du vai, latin, cunéiforme, lisu, perse ancien, ol chiki, bamum, et des idéogrammes issus de langues des 4 coins du globe.

Ces travaux de recherche et de typographie ont été menés conjointement par l’Atelier National de Recherche Typographique de Nancy, l’Institut Designlabor Gutenberg en Allemagne, et le Script Encoding Initiative de l’UC Berkley aux États-Unis.
Il a fallu 18 mois pour proposer 146 glyphes principaux pour ces 146 alphabets manquants, et la création de 66 différentes typographies. En voici quelques uns :

Johannes Bergerhausen et Morgane Pierson, qui ont travaillé sur le missing scripts project racontent que ce travail d’harmonisation des écritures est loin d’être simple. Tout d’abord, il ont analysé et croisé des sources différentes pour cerner les lettres, et les ont fait valider par des spécialistes en écriture. Ensuite, les signes varient souvent selon des dialectes, les régions ou simplement l’écriture manuelle de la personne les ayant inscrits. L’Unicode étant standardisé dans son rendu, il faut parfois modifier l’aspect ou les proportions des signes pour les faire rentrer dans le carré imaginaire qui fait office de norme. Un signe allongé doit ainsi être raccourci, pour “ne pas dépasser”.
C’est ce qu’expliquent les chercheurs dans une conférence à propos du missing scripts project sur YouTube dont on voit une capture ci-dessous. À gauche, les motifs issus des gravures, à droite les propositions des symboles en unicode.


On comprend ici le travail d’harmonisation du signe basé sur les différents scripts existants.
Cette planche montre le retour des spécialistes en écriture, qui aident les chercheurs à définir le bon glyphe Unicode.

Et pour finir en beauté, voici un aperçu graphique d’un glyphe de toutes les langues du monde, vivantes et mortes. Ce poster sérigraphié est disponible à la vente sur le site du world writing system.

Pour aller plus loin sur cette lancée de typographies culturelles mais standardisées, on parlait également de la typo Noto (no tofu) de Google dans notre article sur la typo du futur. Cette dernière est un projet typographique réalisé qui consiste à concevoir digitalement en Unicode des langues peu parlées voir éteintes, et de les rendre vivantes non seulement sur des pierres mais sur des écrans. Moins complète que le MSP, elle converge vers le même souhait de préserver les écritures du monde.
Autre belle histoire, celle de la création de l’AdLam également racontée par Thomas Huot-Marchand dans le podcast Missing Scripts sur le site des 68e rencontres de Lure. Jolie coïncidence de publication !
Sur le même thème
-

Nouvelle identité visuelle Groupama, un logotype en rase campagne
Groupama vient de dévoiler un nouveau logotype qui fait évoluer ses codes graphiques en abandonnant sa campagne au profit d’une esthétique “startup”.
-

Museomix 2012 en 10 prototypes !
10 projets réalisés durant Museomix au Musée gallo-romain de Lyon ! Réalité augmenté, reconnaissance d’images, tables tactiles…